![[운영체제] Linux의 CPU 스케줄링 (CFS 알고리즘)을 파보자!](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F0qATn%2FbtrYEjl2fdH%2FAAAAAAAAAAAAAAAAAAAAACOTB8cWj_4M2Ktva-C357yGsDV8p7pohQVDZ7zX1GyH%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DyVki3vFmO35tTd2dJkFCL%252BOoxnY%253D)
📣
해당 포스트는 운영체제 공룡책과 고건 교수님의 OLC 강의 등을 참고하여 작성되었습니다.
Linux는 CFS(Completely Fair Scheduler)라는CPU 스케줄링 알고리즘을 사용해요!!
CFS는 모든 프로세스가 공평하게 CPU분배를 받도록 하는 동적 우선 순위 기반 알고리즘인데,
이게 무슨 말이냐...
프로세스가 CPU를 기다리는 데 소요한 시간을 계산하여 우선 순위를 동적으로 할당하는 방식입니다.
오랫동안 대기한 프로세스에 더 높은 우선 순위가 부여될 확률이 높은 것이죠.
물론 우선순위는 단순히 기다린 시간에 비례하진 않고, 다양한 조건들을 고려해 종합적으로 매겨집니다.
이번 포스팅에서는 스케쥴링이 어떤 방식으로 이루어지는지 좀 더 자세히 알아보겠습니다!!

1. 타이머 (Timer)
CPU 스케줄링에서 있어서 중요한 것은 시간입니다!
그 시간이라는 것은 무엇일까요??
철학적인 이야기를 하려는 건 아니지만, 컴퓨터가 초침 분침을 보고 있다가 오 시간이 됐다! 이럴리는 없고,
시간을 어떻게 잴 수 있을까요??
이를 알기 위해서는 먼저 HZ와 jiffies에 대해서 알아야 합니다.
타이머 Hz는 1초에 인터럽트가 몇번 걸리는지를 나타냅니다.
만약 HZ를 100으로 설정한다면, 1초에 100번 인터럽트가 걸리게 되는 것이죠!
운영체제는 대부분 100HZ를 사용합니다.
그리고 jiffies는 이 인터럽트가 몇번 일어났는지를 알려주는 count입니다.
만약 어떤 프로세스가 CPU를 받은지 4200 jiffies가 지났고, Hz가 100이라면
4200 / 100 을 해서 42초가 흘렀다는 것을 알 수 있는 것이죠!
즉, 소요 시간 = jiffies / HZ 입니다.
엥? 근데 인터럽트는 I/O 작업할 때만 걸리는거 아니었어??
이런 의문을 가지신다면!! 앞 글들을 다시 보고 오시는 것을 추천드립니다!
왜냐면 CPU가 하나의 프로세스에서 다른 프로세스로 디스패치하는 작업은 커널에서 일어나고,
커널로 가기 위해서는 시스템 콜이 필요한데, 이 작업은 인터럽트를 통해서 일어나기 때문이죠!!
즉, 인터럽트는 I/O 작업 뿐만 아니라 모든 시스템 콜을 처리하기 위해 일어납니다.
그리고 이제 하나 더 시간을 재기 위해서입니다.
CPU 사이클에 맞춰서 증가하다가 특정 값에 도달하면 인터럽트를 생성하는거죠!
1초에 100번은 매우 빨라보이지만, 사실 컴퓨터의 시각에서는 그렇게 빠른건 아닙니다.
제 맥북에 들어가는 M1 pro의 성능 CPU가 3220MHz로 일을 하는데,
1MHz가 100백만Hz이니까 1초에 32억번의 명령 사이클을 도는거죠!!
물론 타이머의 Hz는 인터럽트의 단위이고 CPU 클록 Hz는 사이클의 단위이지만,
그만큼 CPU가 빨라서 100Hz의 인터럽트야... 그렇게 많은 문제가 아니다! 라고 말하고 싶었습니다.

정리하자면, 1초에 100번의 인터럽트를 통해서 시간을 측정하고 있다!! 로 생각하시면 될 것 같습니다!
그럼 100분의 1초보다 작은 단위로는 못세는거야?? 라는 의문이 들었는데요.
찾아보니 정답은 셀 수 있다 입니다!
해당 시간을 가지고 추정해서 더 작은 시간 단위도 추정이 가능하다고 하네요.
정확히 계산이 어떻게 이루어지는 건지는 찾아봐도 잘 안나오는데... 아시는 분은 댓글로 알려주시면 감사하겠습니당 (꾸벅)
(그냥 나누는건강...?)
2. 타임 슬라이스 (Time Slice)
모든 프로세스가 공평하게 CPU를 받는다는 말이 무엇일까요??
결국 모든 프로세스가 동일한 시간만큼 CPU를 받는다는 말과 같습니다!!
그러려면 각각의 프로세스가 얼마나 CPU를 받았는지를 알아야 하는데, 이를 어떻게 알 수 있을까요??
바로 Time Slice를 통해 알 수 있습니다.
TIme Slice는 일종의 시간제한입니다.
선점형 스케줄링의 특성상, 더 높은 priority의 프로세스가 들어오게 되면, 기존의 프로세스는 작업 중에도 CPU를 빼앗기게 되는데
그러다 보면 계속 더 높은 priority의 CPU가 들어오는 경우 영원히 CPU를 받지 못하겠죠??
그래서 리눅스는 Time Slice라는 시간제한을 프로세스마다 부여해서
priority가 높더라도 Time Slice가 0이면 CPU로 디스패치되지 못하도록 하였습니다.
Time Slice를 다 쓴 프로세스는 다른 모든 프로세스들이 Time Slice를 다 소진해야 새로 Time Slice를 받게 되고,
다시 CPU로 디스패치 될 수 있게 하는 방식이죠!
이러면 장기적으로 봤을 때, 모든 프로세스들이 Time Slice의 시간만큼 공평하게 CPU를 받을 수 있게 되는거죠!
보통 프로세스 당 100ms 씩 줍니다ㅎㅎ
3. 리눅스에서 스케줄링이 일어나는 방법
이제 어떻게 스케줄링 하는지에 대해서 설명할게요!!ㅎㅎ
좋은 그림이 있어서 가져왔는데요! 고건 교수님 강의자료입니다.

이 그림은 CPU의 Ready Queue를 도식화 해놓은 그림입니다.
맨 위 그림처럼, 저렇게 Queue에 PCB들이 대기하고 있다가, 자기 차례가 되면 CPU로 들어가는 것이죠.
만약에 CPU가 하나이면 저렇게 일렬로 서있다가 자기 차례가 되면 하나씩 들어가면 되는데,
멀티 프로세스 시스템이 되서 CPU 개수가 많아지면, 엄청 비효율적이겠죠??
왜냐면 쭉 늘어서있는 PCB에서 우선순위가 높은 프로세스를 골라내야 하는데, 저걸 다 찾고 있을 수는 없잖아요?
그래서 약간 절충된 방식이 요거입니다!
우선순위를 좀 나눠서 Queue를 만든거죠!
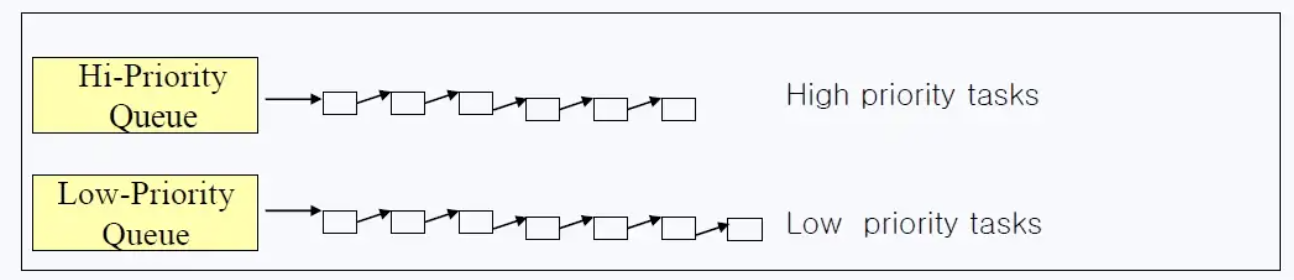
근데... 뒤에 나올 방법과 비교하면 이 방법도 그리 맘에 들지는 않으실거에요ㅎㅎ
현재 리눅스에서 사용하고 있는 Ready Queue는 이 방식입니다!!

보시면 알겠지만, Queue가 확실히 많아졌죠??
저 Queue의 개수는 곧 이야기할 BITMAP_SIZE(비트맵 크기)와 같습니다.
100개 200개가 될 수도 있는데, 중간 중간 비어있는 Queue가 보이잖아요??
이렇게 비어있는 Queue에 굳이 들어가볼 필요가 없기 때문에 만들어진게 Bit map입니다.
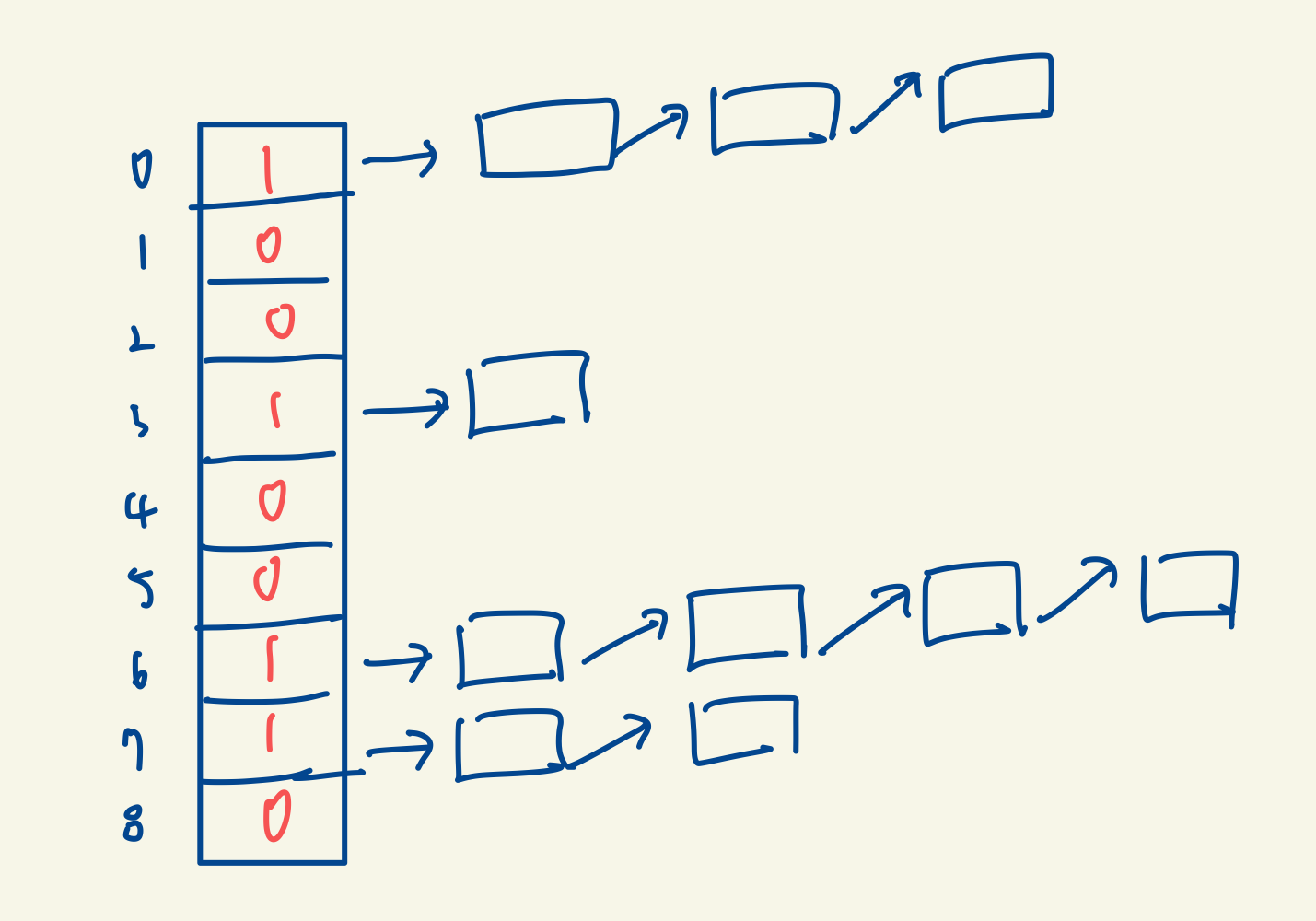
만약에 이렇게 8개의 Queue가 있고, 1,2,4,5,8 인덱스의 Queue가 비어있다면,
[1, 0, 0, 1, 0, 0, 0, 1, 1, 0] 의 Bit map이 되는 것이죠!!
Priorty를 쭉 따라서 내려오면서 저 Bit map을 검사해서 비어있지 않는 Queue만 검사하면 되겠죠??
자 비어 있지 않은 Queue에 들어갔다고 해봅시다.
근데 아까 CFS 스케줄링은 Time Slice가 다 떨어지면 CPU를 받을 수 없다고 했죠??
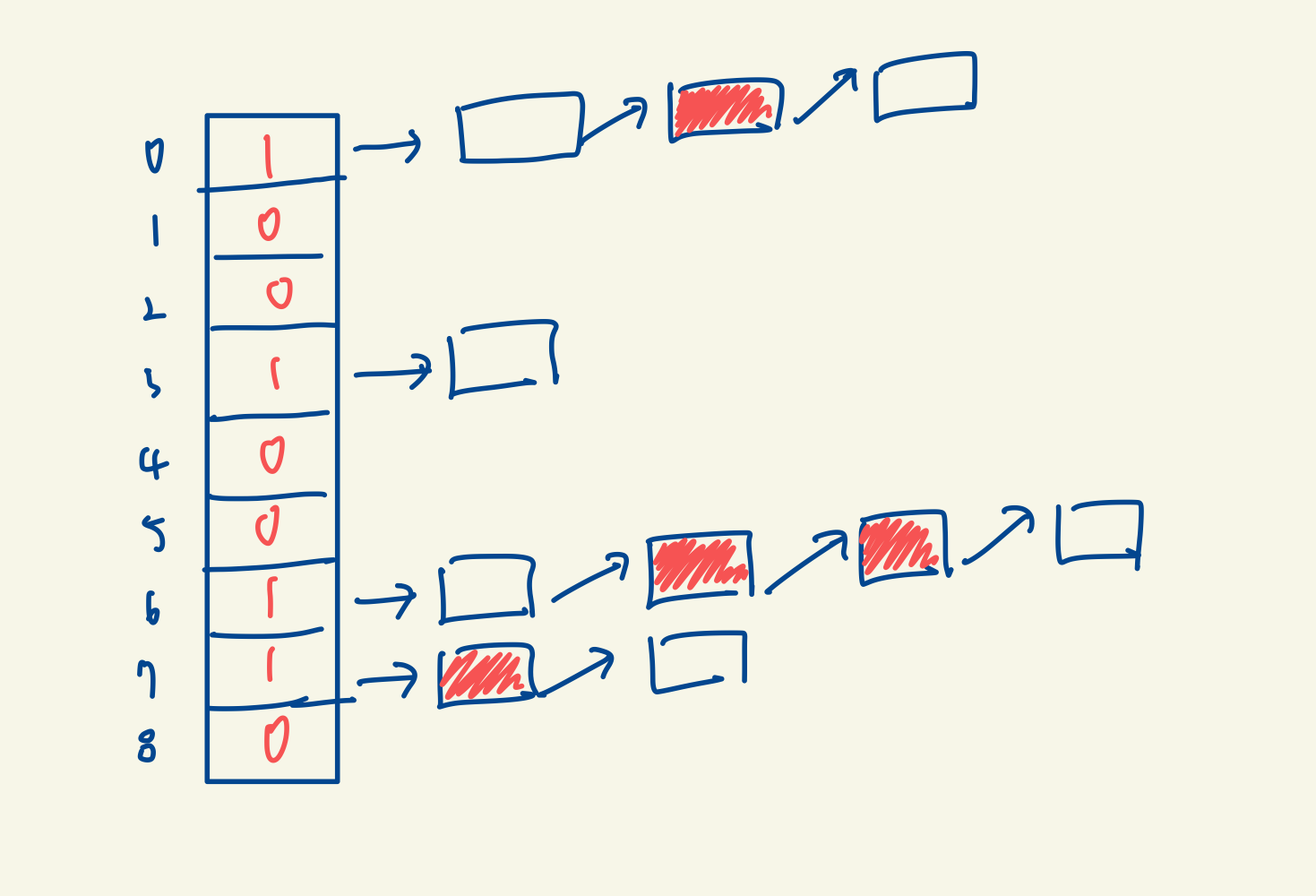
저렇게 Time Slice가 다 떨어진 프로세스를 빨갛게 표현해봤습니다.
그럼 저 프로세스는 어떻게 해야할까요??
바로 Expired Array라는 걸 만들어서 그쪽으로 빼버립니다
이렇게요!!
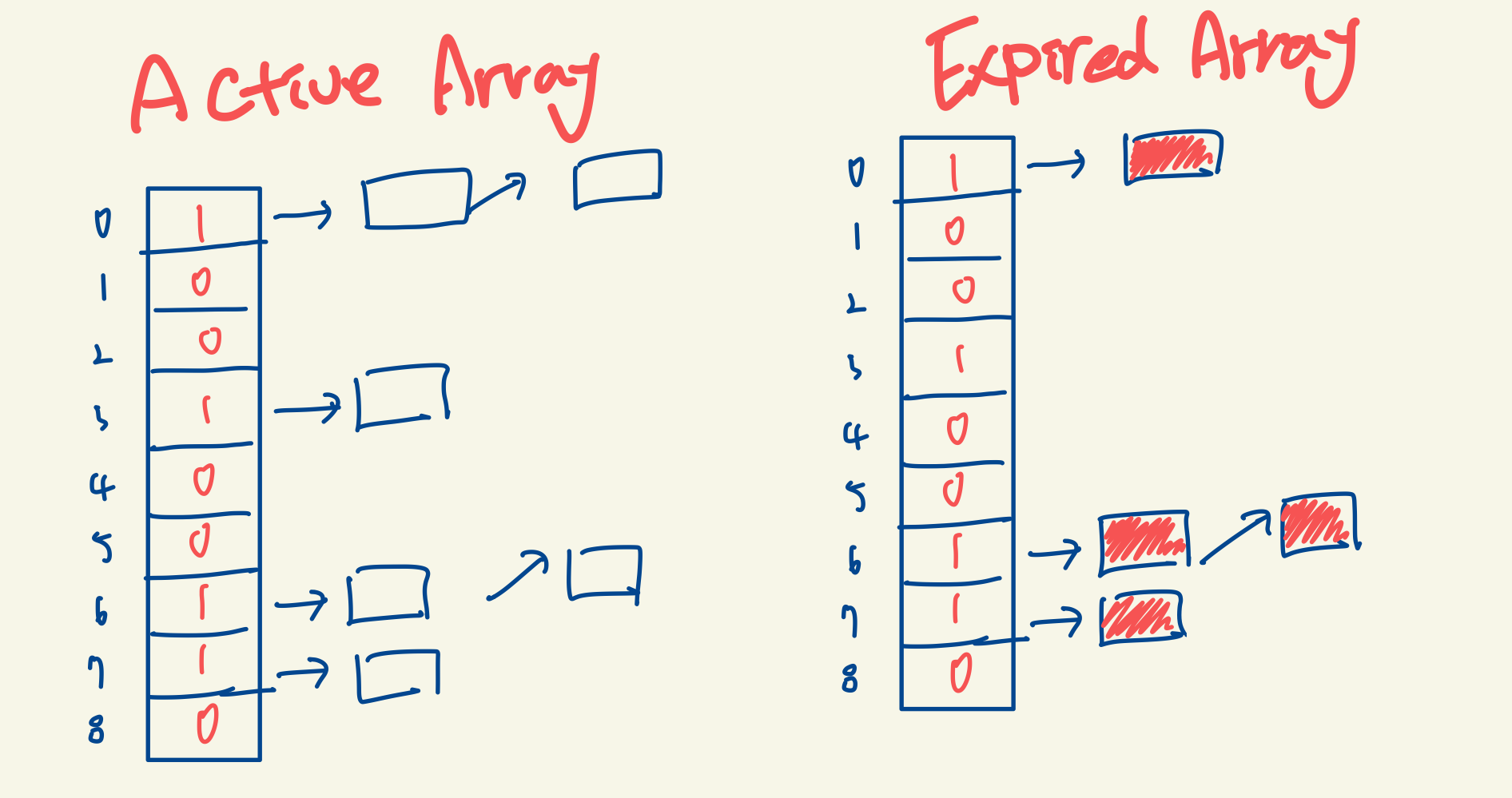
이렇게 스케줄링을 하다보면, Acitve Array에 있는 프로세스들의 Time Slice가 하나씩 다 떨어질테고,
결국 Active Array엔 하나도 남지 않게 되겠죠??
그 때 Exprired Array에 있는 프로세스들의 Time Slice를 일괄적으로 초기화해주고
이때부터 Expired Array가 Active Array로 바뀝니다. 두 Array의 역할이 바뀌는거죠!!
정리가 잘 되셨나요??
오늘은 리눅스의 CFS 스케줄링에 대해서 알아봤는데, 역시 선배님들이 엄청난 고민을 하면서 만들었다는게 느껴지네요.
다음에는 인터럽트에 대해서 설명할게요!!
오늘은 길지는 않았던 글 읽느라 수고 많으셨습니다!!

'운영체제' 카테고리의 다른 글
| [운영체제] 인터럽트(Interrupt) 핸들링을 파보자! (1) | 2023.02.09 |
|---|---|
| [운영체제] 프로세스 생성(fork)을 파보자! (3) | 2023.02.06 |
| [운영체제] System Call(시스템콜)을 파보자! (7) | 2023.02.04 |